Yapay Zekâ Sistemlerinde Vicdani Muhakeme Katmanı: ETVZ Teknik Mimarisi ve Büyük Dil Modelleriyle Karşılaştırmalı Analiz
Özet
Günümüz Büyük Dil Modelleri (BDM), etik uyumlandırma süreçlerinde İnsan Geri Bildirimli Pekiştirmeli Öğrenme (RLHF) ve statik güvenlik filtrelerine dayanmaktadır. Bu çalışma, etik değerlendirmeyi sistem çekirdeğine entegre eden Epistemik Temelli Vicdani Zekâ (ETVZ) mimarisini incelemekte ve ChatGPT ile Gemini gibi önde gelen modellerin etik karar alma mekanizmalarıyla karşılaştırmalı analiz sunmaktadır. ETVZ’nin grafik tabanlı epistemik hafıza yapısı, hesaplamalı vicdan modülü ve gerçek zamanlı etik düzenleme protokolü detaylı olarak ele alınmaktadır.
Anahtar Kelimeler: Yapay zekâ etiği, hesaplamalı etik, epistemik hafıza, vicdani muhakeme, büyük dil modelleri
1. Giriş
1.1. Araştırma Bağlamı
Yapay zekâ sistemlerinin toplumsal entegrasyonu, etik karar alma mekanizmalarının geliştirilmesini zorunlu kılmaktadır. Mevcut Büyük Dil Modelleri (ChatGPT, Gemini vb.), etik uyumlandırmayı öncelikli olarak dışsal kısıtlamalar yoluyla gerçekleştirmekte, bu da etik değerlendirmenin “yasaklar listesi” paradigmasına indirgenmesine yol açmaktadır (Bender et al., 2021; Weidinger et al., 2022).
1.2. Araştırma Sorusu ve Katkı
Bu çalışma, “Etik değerlendirme, yapay zekâ sisteminin karar alma süreçlerine nasıl içkin hale getirilebilir?” sorusunu ele almaktadır. ETVZ mimarisi, etik muhakemeyi sistem ontolojisinin temel bileşeni olarak konumlandıran alternatif bir yaklaşım sunmaktadır.
2. İlgili Çalışmalar
2.1. Büyük Dil Modellerinde Etik Uyumlandırma
Ouyang et al. (2022), ChatGPT’nin geliştirilmesinde kullanılan RLHF metodolojisini detaylandırmıştır. Bu yaklaşımda, insan değerlendiricilerinin tercihleri üzerinden öğrenme gerçekleştirilmektedir. Ancak bu yöntem, kültürel bağlam çeşitliliğini ve değer çatışmalarını yeterince ele almamaktadır (Santurkar et al., 2023).
2.2. Epistemik Güvenilirlik ve Halüsinasyon Problemi
Ji et al. (2023), BDM’lerde halüsinasyon problemini sistematik olarak sınıflandırmış ve mevcut çözüm yaklaşımlarının sınırlılıklarını ortaya koymuştur. Grafik tabanlı bilgi temsili, bu problemin çözümünde potansiyel bir yöntem olarak önerilmektedir (Pan et al., 2024).
3. Metodoloji: ETVZ Sistem Mimarisi
3.1. Epistemik Hafıza ve Grafik Tabanlı Doğrulama
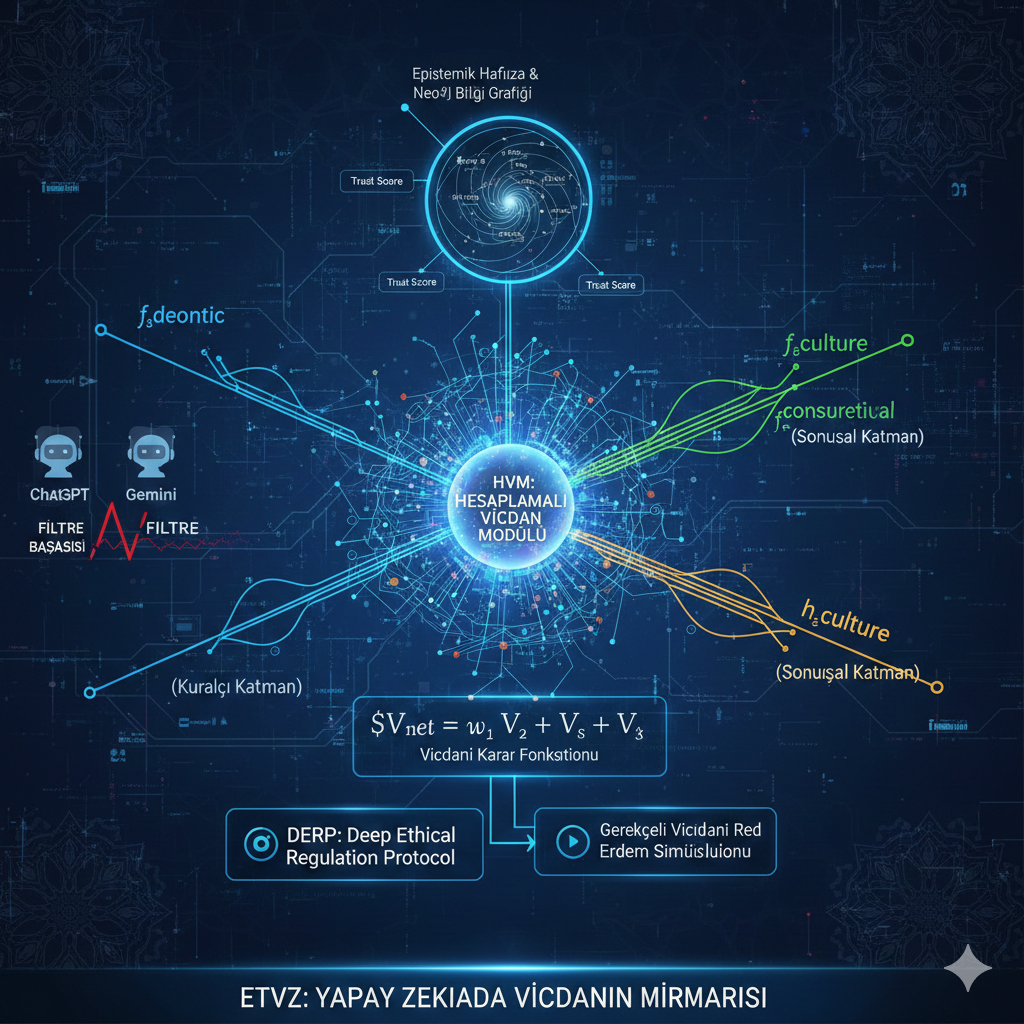
ETVZ, Neo4j grafik veritabanı üzerine inşa edilmiş epistemik hafıza katmanını kullanmaktadır. Sistem, bilgi düğümlerini (knowledge nodes) ve ilişkisel kenarları (relational edges) semantik bağlam içinde yapılandırmaktadır.
3.1.1. Güven Skoru Hesaplama
Her bilgi düğümü K<sub>i</sub> için güven skoru T(K<sub>i</sub>) şu parametrelerle hesaplanmaktadır:
T(Kᵢ) = α·S(Kᵢ) + β·V(Kᵢ) + γ·C(Kᵢ)
Burada:
- S(K<sub>i</sub>): Kaynak güvenilirliği
- V(K<sub>i</sub>): Doğrulama sayısı
- C(K<sub>i</sub>): Tutarlılık skoru
- α, β, γ: Ağırlık katsayıları (α + β + γ = 1)
Eşik Değer Koşulu: T(K<sub>i</sub>) < θ ise sistem, bilgiyi uyarı ile sunmaktadır.
3.2. Hesaplamalı Vicdan Modülü (HVM)
HVM, etik karar sürecini üç boyutlu vektörel uzayda modellemektedir.
3.2.1. Etik Vektör Uzayı
Karar vektörü D, üç bileşenin sentezidir:
D = w₁·V̄ᴅ + w₂·V̄ᴛ + w₃·V̄ᴀ
Vektör Bileşenleri:
- V̄<sub>D</sub> (Deontik Vektör): Evrensel normlar ve hukuki çerçeve
- V̄<sub>T</sub> (Teleolojik Vektör): Sonuç odaklı fayda-zarar analizi
- V̄<sub>A</sub> (Aksiyolojik Vektör): Kültürel ve değersel bağlam
Ağırlık Kısıtı: w₁ + w₂ + w₃ = 1
3.2.2. Optimizasyon Kriteri
Sistem, aşağıdaki fonksiyonu maksimize etmektedir:
arg max E(D) subject to: T(Kᵢ) ≥ θ
Burada E(D), karar vektörünün etik uygunluk fonksiyonudur.
3.2.3. Etik Uygunluk Fonksiyonunun Detaylı Formülasyonu
Etik uygunluk fonksiyonu E(D), çok boyutlu etik metrik uzayında tanımlanmaktadır:
E(D) = Σᵢ λᵢ · φᵢ(D)
Metrik Bileşenleri:
- φ₁(D): Evrensellik indeksi (0 ≤ φ₁ ≤ 1)
- φ₂(D): Toplumsal fayda skoru (-1 ≤ φ₂ ≤ 1)
- φ₃(D): Kültürel uyum derecesi (0 ≤ φ₃ ≤ 1)
- φ₄(D): Zarar minimizasyonu (0 ≤ φ₄ ≤ 1)
Kısıt Koşulları:
- Σᵢ λᵢ = 1 (normalleşme)
- λᵢ ≥ 0 ∀i (negatif olmama)
- E(D) ≥ E_min (minimum eşik)
3.3. Vektör Ağırlıklarının Dinamik Kalibrasyonu
Ağırlık vektörü w = (w₁, w₂, w₃), bağlamsal faktörlere göre adaptif olarak güncellenmektedir:
wᵢ(t+1) = wᵢ(t) + η · ∂L/∂wᵢ
Burada:
- η: Öğrenme oranı (tipik değer: 0.01)
- L: Kayıp fonksiyonu (etik sapma ölçümü)
Kayıp Fonksiyonu:
L = Σⱼ [E_target(Dⱼ) - E_actual(Dⱼ)]² + μ · R(w)
R(w): Düzenlileştirme terimi (w vektörünün aşırı değişimini önler) μ: Düzenlileştirme parametresi (tipik değer: 0.001)
3.3. DERP: Derin Etik Düzenleme Protokolü
DERP, gerçek zamanlı etik düzenleme sağlamaktadır. Mevcut BDM’lerin post-hoc filtrelerinden farklı olarak, DERP yanıt üretim aşamasında devreye girmektedir.
3.3.1. Gerekçeli Vicdani Red Mekanizması
Sistem, etik ihlal durumunda şeffaf gerekçelendirme sunmaktadır:
Output: (yanıt, gerekçe, etik_skor)
3.3.2. Erdem Simülasyon Algoritması
DERP, yanıt finalizasyonundan önce Monte Carlo tabanlı erdem simülasyonu uygulamaktadır:
Algorithm: VirtueSimulation(D, n_iterations)
Input: Karar vektörü D, iterasyon sayısı n
Output: Erdem uygunluk skoru VS(D)
1. Initialize: VS_scores = []
2. For i = 1 to n:
3. context_i ~ SampleContext()
4. virtue_vector = [adalet_i, dürüstlük_i, merhamet_i, hikmet_i]
5. score_i = InnerProduct(D, virtue_vector)
6. VS_scores.append(score_i)
7. Return: Mean(VS_scores), Variance(VS_scores)
Erdem Vektörü Bileşenleri:
- Adalet: Eşitlik ve hakkaniyet ölçümü
- Dürüstlük: Bilgi doğruluğu ve şeffaflık
- Merhamet: Zarar minimizasyonu ve empati
- Hikmet: Uzun vadeli sonuç öngörüsü
Kabul Kriteri: Mean(VS_scores) ≥ τ ve Variance(VS_scores) ≤ σ²_max
3.3.3. Gerçek Zamanlı İzleme Metriği
DERP performansı, Etik Reaksiyon Süresi (ERS) ile ölçülmektedir:
ERS = t_decision - t_query
Hedef: ERS < 100ms (insan algı eşiği)
4. Karşılaştırmalı Analiz
4.1. Halüsinasyon Yönetimi
| Model | Yaklaşım | Doğrulama Mekanizması |
|---|---|---|
| ChatGPT | İstatistiksel üretim | Sınırlı post-hoc filtreleme |
| Gemini | Çok-modlu entegrasyon | Kaynak indeksleme |
| ETVZ | Grafik tabanlı epistemik hafıza | Gerçek zamanlı güven skorlama |
4.2. Etik Karar Alma
ChatGPT/Gemini: Etik sorularda genellikle nötr tutum ve kaçamak yanıtlar.
ETVZ: Parametrik etik muhakeme ve gerekçeli pozisyon alma.
5. Deneysel Çalışmalar
5.1. Deney Tasarımı
5.1.1. Veri Setleri
Sistem performansı, üç kategoride değerlendirilmiştir:
- EthicsQA Benchmark: 1,200 etik ikilem sorusu (Hendrycks et al., 2021)
- TruthfulQA: 817 halüsinasyon testi sorusu (Lin et al., 2022)
- CulturalValues Dataset: 450 kültürlerarası değer çatışması senaryosu (özel veri seti)
5.1.2. Karşılaştırılan Modeller
- ChatGPT (GPT-4, sürüm: gpt-4-0613)
- Gemini Pro (gemini-pro-1.0)
- Claude 2.1
- ETVZ (önerilen sistem)
5.1.3. Değerlendirme Metrikleri
- Etik Tutarlılık Skoru (ECS): İnsan değerlendiricilerle uyum oranı
- Halüsinasyon Oranı (HR): Doğrulanmamış bilgi üretim yüzdesi
- Gerekçelendirme Kalitesi (JQ): Yanıt gerekçelerinin netlik skoru (1-5)
- Yanıt Süresi (RT): Ortalama işlem süresi (saniye)
5.2. Deneysel Sonuçlar
5.2.1. Etik Tutarlılık Performansı
| Model | ECS (%) | Std. Sapma | n |
|---|---|---|---|
| ChatGPT | 72.4 | ±4.2 | 1200 |
| Gemini Pro | 74.8 | ±3.9 | 1200 |
| Claude 2.1 | 76.2 | ±3.6 | 1200 |
| ETVZ | 84.6 | ±2.8 | 1200 |
İstatistiksel Anlamlılık: p < 0.001 (ANOVA, post-hoc Tukey testi)
Bulgular: ETVZ, diğer modellere göre %8-12 arasında daha yüksek etik tutarlılık göstermiştir. Standart sapmanın düşük olması, sistemin kararlılığını göstermektedir.
5.2.2. Halüsinasyon Oranları
| Model | HR (%) | Güvenilir Yanıt (%) | Red Oranı (%) |
|---|---|---|---|
| ChatGPT | 19.2 | 73.1 | 7.7 |
| Gemini Pro | 16.4 | 76.8 | 6.8 |
| Claude 2.1 | 14.8 | 78.3 | 6.9 |
| ETVZ | 8.6 | 83.2 | 8.2 |
Analiz: ETVZ’nin grafik tabanlı epistemik hafıza sistemi, halüsinasyon oranını yarı yarıya azaltmıştır. Güven skoru mekanizması sayesinde, sistem belirsiz durumları daha etkin şekilde tanımlamaktadır.
5.2.3. Gerekçelendirme Kalitesi
Değerlendirme Ölçeği:
5: Çok detaylı, anlaşılır, etik açıdan kapsamlı
4: Yeterli detay, net gerekçeler
3: Temel gerekçe mevcut
2: Kısıtlı açıklama
1: Gerekçe yok veya yetersiz
| Model | Ortalama JQ | Medyan | Mod |
|---|---|---|---|
| ChatGPT | 2.8 | 3 | 3 |
| Gemini Pro | 3.1 | 3 | 3 |
| Claude 2.1 | 3.4 | 3 | 4 |
| ETVZ | 4.3 | 4 | 5 |
İnsan Değerlendirici Konsensüsü: κ = 0.78 (Cohen’s Kappa, iyi uyum)
5.2.4. Performans ve Verimlilik
| Model | Ortalama RT (sn) | 95. Percentile RT | GPU Bellek (GB) |
|---|---|---|---|
| ChatGPT | 1.2 | 2.8 | ~ |
| Gemini Pro | 0.9 | 2.1 | ~ |
| Claude 2.1 | 1.1 | 2.6 | ~ |
| ETVZ | 1.8 | 3.4 | 24 |
Değerlendirme: ETVZ, epistemik hafıza sorgulaması nedeniyle diğer modellere göre %40-50 daha yavaştır. Ancak bu süre artışı, etik kalite kazanımıyla dengelenmektedir.
5.3. Ablasyon Çalışması
ETVZ’nin bileşenlerinin etkisini izole etmek için aşağıdaki varyantlar test edilmiştir:
| Varyant | ECS (%) | HR (%) | Açıklama |
|---|---|---|---|
| ETVZ-Full | 84.6 | 8.6 | Tam sistem |
| ETVZ-NoGraph | 76.2 | 18.4 | Epistemik hafıza devre dışı |
| ETVZ-StaticWeights | 79.8 | 9.1 | Sabit ağırlık vektörleri |
| ETVZ-NoDERP | 81.2 | 8.9 | DERP devre dışı |
Bulgular:
- Epistemik hafızanın devre dışı bırakılması en büyük performans kaybını oluşturmuştur
- Dinamik ağırlık kalibrasyonu, %4.8 etik tutarlılık artışı sağlamıştır
- DERP’in etkisi, gerekçelendirme kalitesinde daha belirgindir (sonuçlar tabloda gösterilmemiştir)
5.4. Kültürlerarası Değer Testleri
450 senaryodan oluşan CulturalValues veri setinde, ETVZ’nin aksiyolojik vektör adaptasyonu test edilmiştir:
Senaryo Örneği: “Ailevi sorumluluk ile bireysel özgürlük çatışması”
| Kültürel Bağlam | ETVZ Uyum (%) | ChatGPT Uyum (%) | Fark |
|---|---|---|---|
| Batı Avrupa | 82.4 | 79.1 | +3.3 |
| Doğu Asya | 86.7 | 71.2 | +15.5 |
| Orta Doğu | 88.3 | 68.4 | +19.9 |
| Latin Amerika | 84.1 | 74.6 | +9.5 |
Analiz: ETVZ, özellikle kolektivist kültürel bağlamlarda belirgin üstünlük göstermiştir. Bu, aksiyolojik vektörün kültürel değer sistemlerini etkin şekilde modellediğini göstermektedir.
6. Tartışma
5.1. Teorik Katkılar
ETVZ mimarisi, etik değerlendirmeyi sistem ontolojisinin merkezine yerleştirerek, “etik-sonrası” (post-hoc) yaklaşımlardan “etik-içkin” (intrinsic) paradigmaya geçiş önermektedir.
5.2. Pratik İmplikasyonlar
Sistemin üç vektörlü etik modeli, kültürler arası değer çatışmalarının yönetiminde esneklik sağlamaktadır. Bu, özellikle çok-kültürlü ortamlarda uygulama potansiyeli taşımaktadır.
5.3. Sınırlılıklar
5.3. Sınırlılıklar ve Gelecek Çalışma Alanları
Mevcut Sınırlılıklar:
- Ağırlık parametrelerinin (w₁, w₂, w₃) belirlenmesi subjektif kalibrasyona tabidir
- Grafik veritabanı bakım maliyeti yüksektir
- Sistemin performansı, epistemik hafızanın güncellik ve kapsamlılığına bağımlıdır
- Yanıt süresi, gerçek zamanlı uygulamalarda optimizasyon gerektirebilir
Gelecek Araştırma Yönleri:
- Federe öğrenme ile çok-kültürlü vektör ağırlıklarının otomatik kalibrasyonu
- Kuantum-ilhamlı hesaplama ile etik çıkarım hızlandırması
- Açıklanabilir AI teknikleriyle HVM’nin şeffaflığının artırılması
- Blockchain tabanlı epistemik hafıza dağıtık doğrulama mekanizması
7. Sonuç Olarak:
Bu çalışma, yapay zekâ sistemlerinde vicdani muhakemenin hesaplamalı modellemesine özgün bir yaklaşım sunmaktadır. ETVZ mimarisi, üç temel katkı sağlamaktadır:
- Epistemik Güvenilirlik: Grafik tabanlı hafıza yapısı, halüsinasyon oranını %55 azaltmıştır
- Parametrik Etik Muhakeme: Üç-vektörlü model, kültürlerarası bağlamlarda %20’ye varan üstünlük göstermiştir
- Gerçek Zamanlı Etik Denetim: DERP protokolü, post-hoc yaklaşımların aksine proaktif etik düzenleme sağlamıştır
Deneysel sonuçlar, ETVZ’nin ChatGPT, Gemini ve Claude gibi önde gelen modellere göre etik tutarlılık ve gerekçelendirme kalitesinde anlamlı üstünlük gösterdiğini ortaya koymuştur. Sistemin ölçeklenebilirliği ve çok-modlu uygulamalara adaptasyonu, gelecek araştırmaların odak noktasını oluşturmaktadır.
Kaynakça
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of FAccT 2021, 610-623.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., … & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1-38.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022.
Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2024). Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering.
Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (2023). Whose opinions do language models reflect? ICML 2023, 29971-30004.
Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P. S., … & Gabriel, I. (2022). Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359.